Continuous Integration
Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates
at least daily - leading to multiple integrations per day. Each integration is verified by an automated build (including test)
to detect integration errors as quickly as possible. Many teams find that this approach leads to significantly reduced integration
problems and allows a team to develop cohesive software more rapidly.
- Martin Fowler, martinfowler.com
Continuous Integration can also be extended to automate other common activities, such as deployment and monitoring. The result is a much faster turn around time from design to deployment, with the added ability to keep an automated eye on the current state of things. The constant integration and error checking helps create a more stable product and provides a consistent window into the state of the current system, while the automation provides the ability to perform complex operations either automatically or at the press of a button.
The Challenge
How does one configure continuous integration in an existing development infrastructure? Where do you start, and what tools and technologies do you need?
Before you start having to worry about tools and technologies you first need to consider what type of an environment you have, and what type of an environment you need.
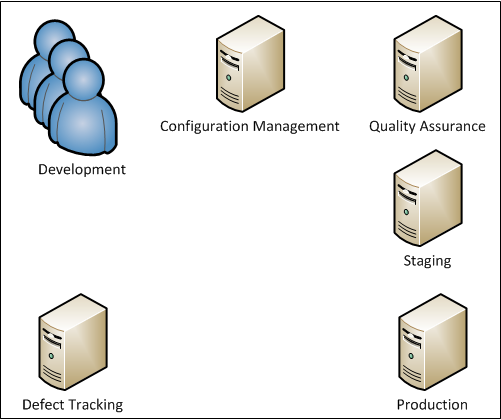
The Environment
Any basic modern software development environment should consist of the following:
- Development
- Configuration Management
- Quality Assurance
- Staging
- Production
- Defect Tracking
If any of these items are missing you are going to need to get them in place to be able to do any type of continuous integration, and to effectively version and test your system.
Development - This refers to each individual developer's machine, which must consist of the appropriate Integrated Development Environment (IDE) and must be able to run the system. Ideally the system should also be runnable out of the IDE, which is a big time saver.
Configuration Management - The refers to the software configuration management server that is responsible for tracking and controlling code changes. SCM concerns itself with answering the question "Somebody did something, how can one reproduce it?"
Quality Assurance - Refers to the server which is at a team accessible location where the more recent version of the system has been deployed. This is a good target for an automated deployment, since the purpose of this environment is to be the more recent version. This is also a good place to run integration and acceptance tests, to ensure system integrity in an automated fashion.
Staging - Refers to the server which is at a team accessible location, and that is as close to production as possible. The purpose of this environment is to serve as a non-customer facing production clone which can be used for manual testing, and serves as a verification that the system here is ready to be deployed to production.
Production - Refers to the location to which your system is deployed, and which customers currently use.
Defect Tracking - Refers to any system which you use to track defects, feature requests, and any other tasks related to making changes on a system. It answers the questions "what is wrong, what needs to change, and who is working on what?"
Where Continuous Integration Fits
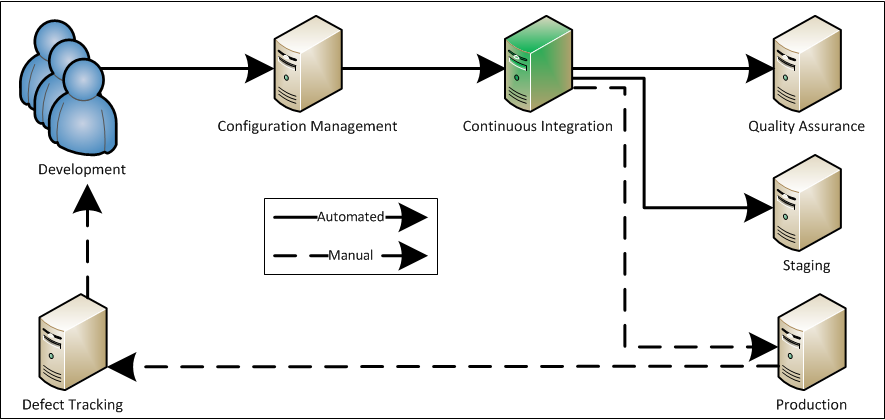
Continuous Integration is used in the following process:
1. Check-In: Developers check-in code to SCM
2. Wait for changes: The CI server polls SCM at some interval, looking for code changes
3. Build and test: When the CI Server detects a code change, it runs the system unit tests and then the build
4. Deploy to QA: On the pass of unit tests and the build, the CI server deploys the system to the QA environment
5. Integration and Acceptance test: The QA environment is now capable of running integration and acceptance tests pending an automated database refresh
6. Deploy to Staging: On the pass of integration and acceptance tests, the CI server deploys the system to the Staging environment
7. Verify Staging: On manual acceptance of the state of the system in the Staging environment, the system is ready to be deployed to production
8. Deploy to Production: A CI Task can then be manually run by pressing a button that deploys the system to production
9. Issues and Features: Production issues and feature requests can then be entered into the defect tracking system (or at any point in the process), to later be assigned to be worked
The Build Process
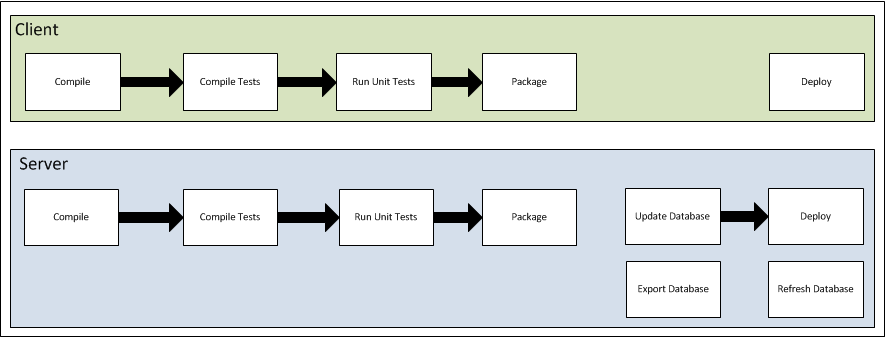
Assuming a three tier architecture with a separate client, server, and database there are three aspects to an automated build.
1. The Client Build - Must be able to compile, run unit tests, and package the client portion of the system for deployment.
2. The Server Build - Must be able to compile, run unit tests, package the client portion of the system for deployment, and be able to call the database build
3. The Database Build - Generally part of the server build, must provide the ability to create a database from scratch, apply updates, export the data from the database, and refresh the data in the database from an export.
From a process perspective the client and server can be deployed independently, but the server deployment is tied to the database. This is because server projects contain entity mappings to the database, which generally ties the two together together.
A Database Build?
From a production management perspective changes to the database have to be tightly controlled. You just can't drop and create the database every time you need to make a change, because that would obviously delete new data that had been created as the result of end users working on your system. There needs to be some mechanism for applying an update to the database, which manipulates the exiting data and structure while leaving the database intact.
From a developer setup perspective, developers that come on later in the project need to be able to re-create the database in the same state that exists in production, or on which the other developers are currently working. This requires that you track the updates that are made to the database.
From a testing and maintenance perspective, the ability to save off a state of the database and later restore it is required in order to run true acceptance tests. For example if your automated acceptance test includes creating a new user named Bob you can only do that once. Refreshing the database allows you to continually run acceptance tests and then return the state of the database to what it was previously, so that you don't have to create smarter scripts that use different usernames and such every time they run. This also allows developers to import the states of databases used by QA in order to more easily reproduce problems related to data.
These needs result in a build that provides the ability to create a database from scratch, by which the initial database is created and then all updates since its creation are then applied, and also allows the saving and refreshing of data.
The Build Scenarios
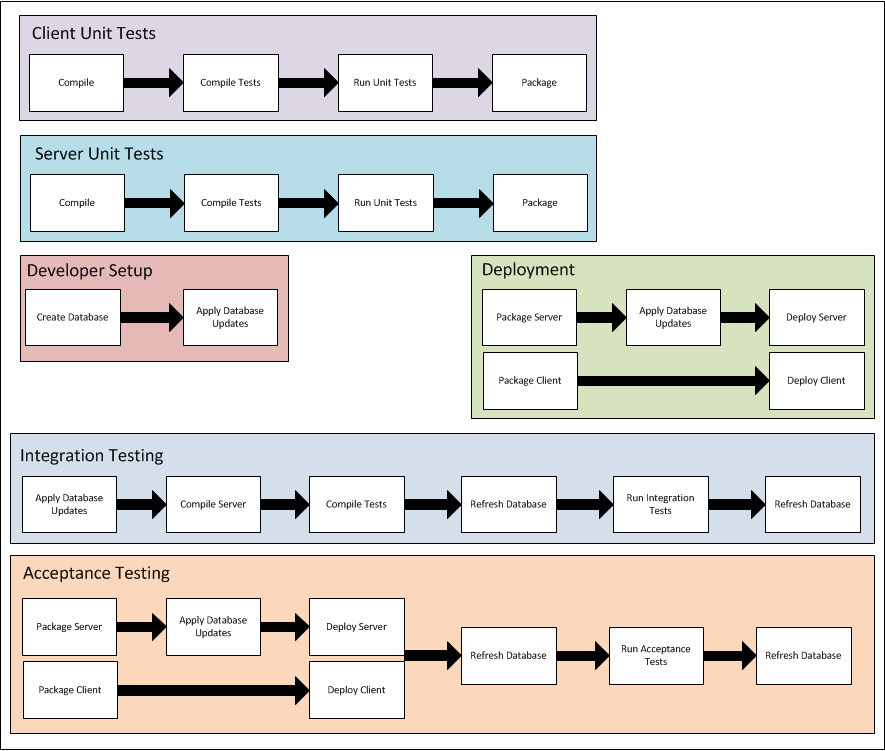
The purpose of the client, server, and database builds is to support the following 6 scenarios:
1. Client Unit Tests - The scenario for running client unit tests, and then packaging the client
2. Server Unit Tests - The scenario for running server unit tests, and then packaging the server
3. Developer Setup - The scenario for configuring the database for the first time
4. Deployment - The scenario for deploying the server and/or client to a particular environment
5. Integration Testing - The scenario for running integration tests for the system. Integration tests are tests that verify the behavior of server to database operations, along with any other integration points. There are also tools and techniques for running integration tests against an undeployed system and reverting the database on a test by test basis.
6. Acceptance Testing - The scenario for deploying the system and running acceptance tests against it. Acceptance tests are tests that drive the graphical user interface using pre-recorded actions in order test overall system functionality, such as logging in, creating an account, and so on.
Applying the Build Scenarios
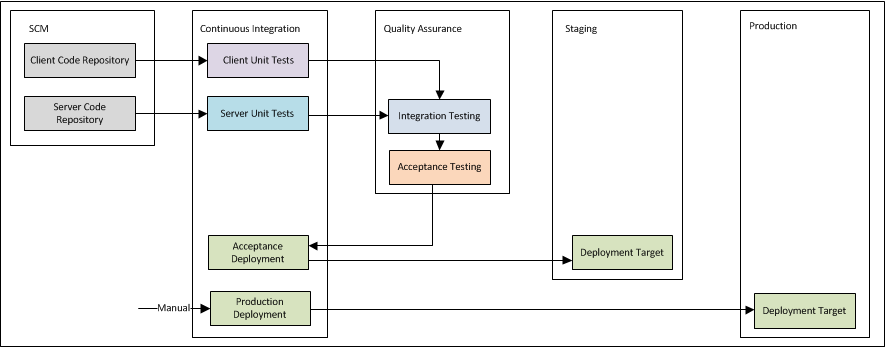
Continuous Integration is used in the following process according to the build scenarios:
1A. Client Code Repository: Developers check-in code changes
1B. Server Code Repository: Developers check-in code changes
2A. Client Unit Tests: The CI server polls SCM at some interval, looking for code changes. When found it runs the client unit testing scenario
2B. Server Unit Tests: The CI server polls SCM at some interval, looking for code changes. When found it runs the server unit testing scenario
3. Integration Testing: On the pass of either the client and/or server build, the CI server runs the integration testing scenario. This is a task where you want to maintain a lock, as you do not want multiples of this task or any other related downstream task running after this part of the process has started.
4. Acceptance Testing: On the pass of integration testing, the acceptance testing scenario now runs. This is another task that needs to maintain the same lock.
5. Staging Deployment: On the pass of acceptance tests, the CI server deploys the system to the Staging environment. This is another task that needs to maintain the same lock.
6. Production Deployment: On manual acceptance of the state of the system in the Staging environment the system is ready to be deployed to production.
Technologies Used
The process described was primarily accomplished using a combination of the Jenkins/Hudson CI server and the AF Ant Framework, which contains complex macros for compiling, testing, packaging, deploying, and database management through Ant in various technologies.
- Client Technologies: Ext JS 4, RichFaces, Flex
- Server Technologies: Spring, EJB 3.0, SEAM 2
- Continuous Integration Servers: Jenkins, Hudson
- Build Automation: Ant + AF Ant Framework
- Unit Testing: JUnit + AF Ant Framework (Java), Flex Unit + AF Ant Framework (Flex)
- Integration Testing: JUnit + AF Ant Framework (Java)
- Acceptance Testing: Selenium (HTML), QTP (Flex)
- Defect/Task Tracking: Bugzilla, Pivotal, FogBugz
- Databases: MySQL, MS SQL, Oracle, MongoDB
- SCM: Subversion
- Servers: Windows, Linux
- Dependency Management: Ivy
- Database Change Management: dbdeploy + AF Ant Framework
- Database Import/Export: dbunit + AF Ant Framework